本文详细讲解了从卷积神经网络到Transformer的深度学习发展趋势,介绍了Transformer的背景、核心算法原理以及具体代码实例和解释。同时,本文还对Transformer的未来发展趋势和挑战进行了深入分析。最后,本文总结了...
”神经网络 深度学习 transformer“ 的搜索结果

transformer模型详细介绍

作者:禅与计算机程序设计艺术 《深度学习中的 Transformer 应用》 1. 引言 随着深度学习技术的快速发展,Transformer 模型的出现

最近在做论文,需要使用transformer模型进行时间序列数据的预测。目前matlab深度学习工具箱中好像没有这个模块?本人不会写代码,请问有什么第三方的工具箱或者其他解决方案吗? 感谢各位!!
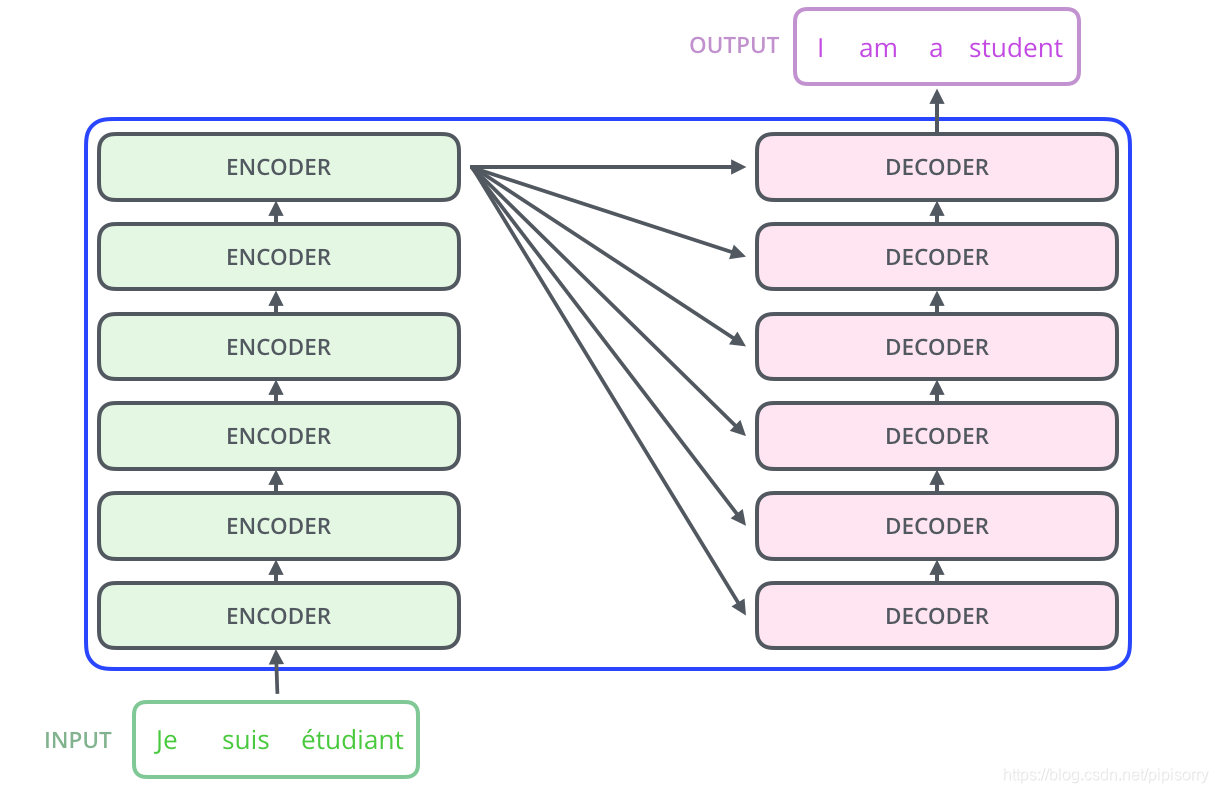

最近神经网络结构Transformer非常流行,先后席卷了NLP和CV,大有取代CNN一统天下之势。 Transformer中文名是变形金刚的意思。

现为**南洋理工大学助理研究员的 Chaitanya Joshi 将为读者介绍图神经网络和 Transformer 之间的内在联系**。具体而言,作者首先介绍 **NLP 和 GNN 中模型架构的基本原理**,使用公式和图片来加以联系,然后讨论怎样...
今天具体介绍一个Google DeepMind在15年提出的Spatial Transformer Networks,相当于在传统的一层Convolution中间,装了一个“插件”,可以使得传统的卷积带有了[裁剪]、[平移]、[缩放]、[旋转]等特性;理论上,作者...

基于transformer神经网络的汉蒙机构名翻译研究.pdf
深度学习入门-4(机器翻译,注意力机制和Seq2seq模型,Transformer)一、机器翻译1、机器翻译概念2、数据的处理3、机器翻译组成模块(1)Encoder-Decoder框架(编码器-解码器)(2)Sequence to Sequence模型(3)集...
译文质量估计中基于Transformer的联合神经网络模型.pdf
神经网络也是以类似的方式工作。它由大量的人工神经元组成,每个神经元类似于一个小的计算单元。每个神经元接收来自其他神经元的输入,并通过一个称为激活函数的非线性函数来处理这些输入。激活函数决定了神经元是否...

复旦大学_深度学习与神经网络书籍
标签: 深度学习
我们不仅能了解到全连接、卷积和循环等基本深度神经网络网络,同时还能学习到前沿的 Transformer 等模型,当然所需的数学基础在附录也都是有提供的。这本 446 页的深度学习开放教科书,足够我们了解 DL 的前前后后。
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的** 顺序结构**,使得模型可以并行化训练...
基于CNN、LSTM、Transformer以及BERT各种神经网络进行情感分类项目源码.zip本资源中的源码都是经过本地编译过可运行的,资源项目的难度比较适中,内容都是经过助教老师审定过的能够满足学习、使用需求,如果有需要的...


Transformer是一个Seq2Seq(Sequence-to-Sequence)的模型,这意味着它能够处理从输入序列到输出序列的问题。在Seq2Seq模型中,输入是一段序列,输出也是一段序列,输出序列的长度通常由模型自身决定。这种模型在...
最后,再介绍一种人工神经网络:前馈神经网络(Feedforward Neural Networks,FNNs)。将一种语言的文本翻译为另一种语言。适用场景:用于序列数据处理,与 LSTM 类似。将图像分类为不同的物体或场景。案例:股票...
目前机器学习的替代者深度学习(卷积神经网络)基于卷积神经网络,设计一个基于深度学习的车牌检测识别系统,用于本科毕业论文可以说是非常合适的,这篇博文记录的就是一篇本科毕业设计所用到的模型算法,训练这个...

机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。 1.Encoder-...

推荐文章
- MFC 自定义消息(类向对话框类传递自定义消息)-程序员宅基地
- Openstack 控制台开发体会_openstack console开发-程序员宅基地
- 电流检测电路_ina180-程序员宅基地
- CentOS 7下安装Kafka集群_centos7安装kafka集群-程序员宅基地
- 公钥私钥加解密原理_公钥加解密-程序员宅基地
- 项目管理-概述_项目过程控制 确保 项目 资金-程序员宅基地
- 记录nvm use node.js版本失败,出现报错: exit status 1: ��û���㹻��Ȩ��ִ�д˲�����_nvm use失败-程序员宅基地
- lua面向对象编程之点号与冒号的差异详细比较-程序员宅基地
- 百度云虚假下载_虚假新闻:关于公共云的5种常见误解-程序员宅基地
- Tesseract图像识别OCR的学习1_tesseract doocr-程序员宅基地